Sehr geehrter Kunde
Herzlichen Dank, dass Sie sich für Hoststar als Ihren Webhosting-Provider entschieden haben. Ihr Webhosting wurde installiert und steht für den Datenupload bereit. Wir wünschen Ihnen viel Freude und Erfolg mit Ihrem neuen Webhosting!
Liebe Besucher
Möchten Sie gutes und günstiges Webhosting?
Für nur CHF 9.90 pro Monat erhalten Sie bei Hoststar 100 GB Web-Speicherplatz, 100 GB Cloud-Speicher, unlimitiert viele E-Mail-Postfächer, unlimitiert MySQL-Datenbanken und viele weitere Dienstleistungen.
Alles im Griff
Ein Login für alles – das ist das My Panel von Hoststar. Es bietet Ihnen zentral sämtliche Funktionen, welche für die Verwaltung Ihrer Dienste nötig sind, in einem modernen und übersichtlichen Design.
Mehr über My Panel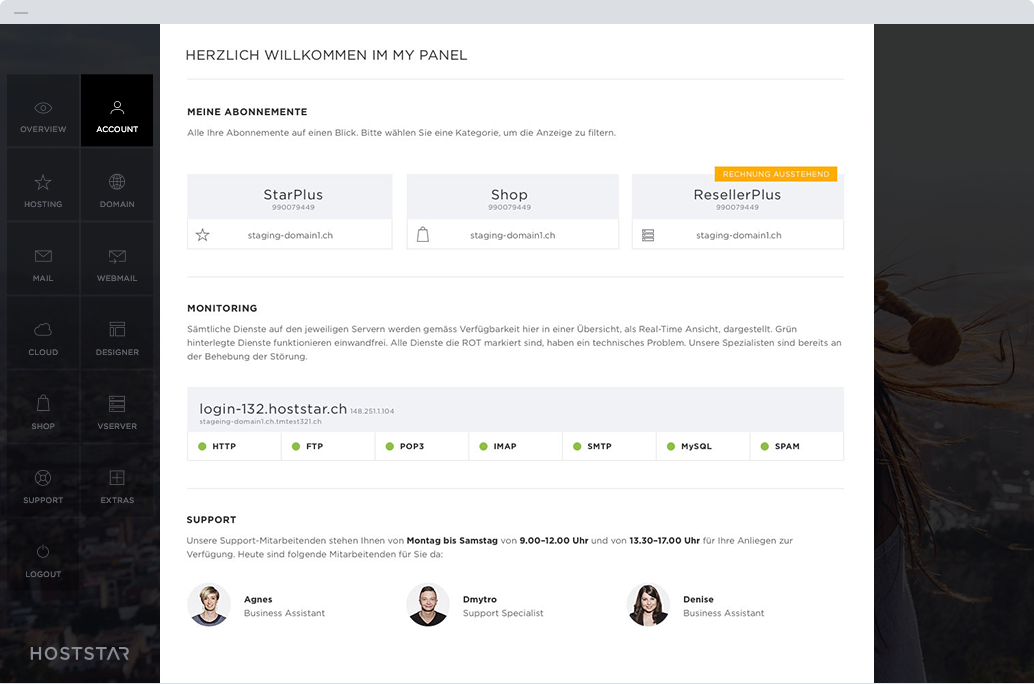
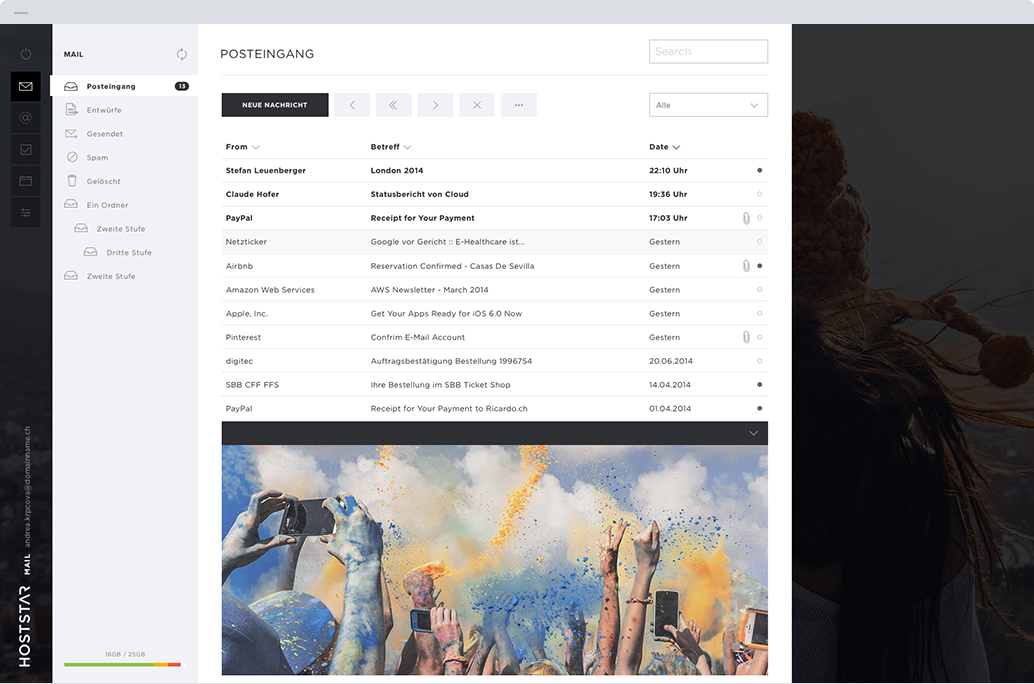
Perfektes Webmail
Die einfache und elegante Webmail-Bedienoberfläche bietet den von Desktop-Programmen gewohnten Luxus. Von jedem Browser mit Internetzugang aus erreichbar, ist Webmail die perfekte Lösung, wenn Sie beispielsweise unterwegs von einem fremden Gerät bequem auf Ihre E-Mails zugreifen wollen. Selbstverständlich lässt sich Mail auch in Ihre E-Mail-Applikation einbinden.
Mehr über WebmailDas perfekte Hosting für Sie
Ob StarEntry, StarBiz oder StarPlus – unsere Webhosting-Angebote für Sie sind vollgepackt mit einzigartigen Features, welche Sie für Ihren professionellen Webauftritt brauchen.

30 Tage Geld-zurück-Garantie
Cloud Inklusive
In Ihrer persönlichen Cloud von Hoststar speichern Sie Ihre Dateien, Fotos, Musik und Videos, auf die Sie weltweit zugreifen können. Zu jedem Hosting- und Website-Paket erhalten Sie Ihre persönliche Cloud kostenlos dazu.


Webseite-Designer mit genialem Editor
Erstellen Sie Ihre professionelle Website im Handumdrehen mit dem Designer von Hoststar. Mit unserem Editor gestalten Sie Ihre Website ganz nach Ihren persönlichen Vorstellungen – dank den individuellen Anpassungsmöglichkeiten für Tabellen, Buttons, Farben und Bilder. Texte und Bilder schieben Sie ganz einfach per Drag & Drop an die gewünschte Position. Professionelles Webdesign ohne Programmierkenntnisse!
Mehr über DesignerSchweiz - Hauptsitz
HOSTSTAR - Multimedia Networks AG
Kirchgasse 30
CH-3312 Fraubrunnen
Telefon +41 (0)848 00 80 80
Fax +41 (0)31 760 10 44
Website www.hoststar.ch
Mail servicecenter@hoststar.ch
Österreich - Niederlassung
HOSTSTAR - Multimedia Networks AG
Irdning 186
A-8952 Irdning
Telefon +43 (0)676 566 82 84
Fax +43 (0)662 234 66 23 23
Website www.hoststar.at
Mail servicecenter@hoststar.at